Основы ELK
Основы ELK
- Документоориентированная БД
Индекс
Использует обратные индексы: ключи - все используемые слова, значения - сущности, содержащие эти слова.
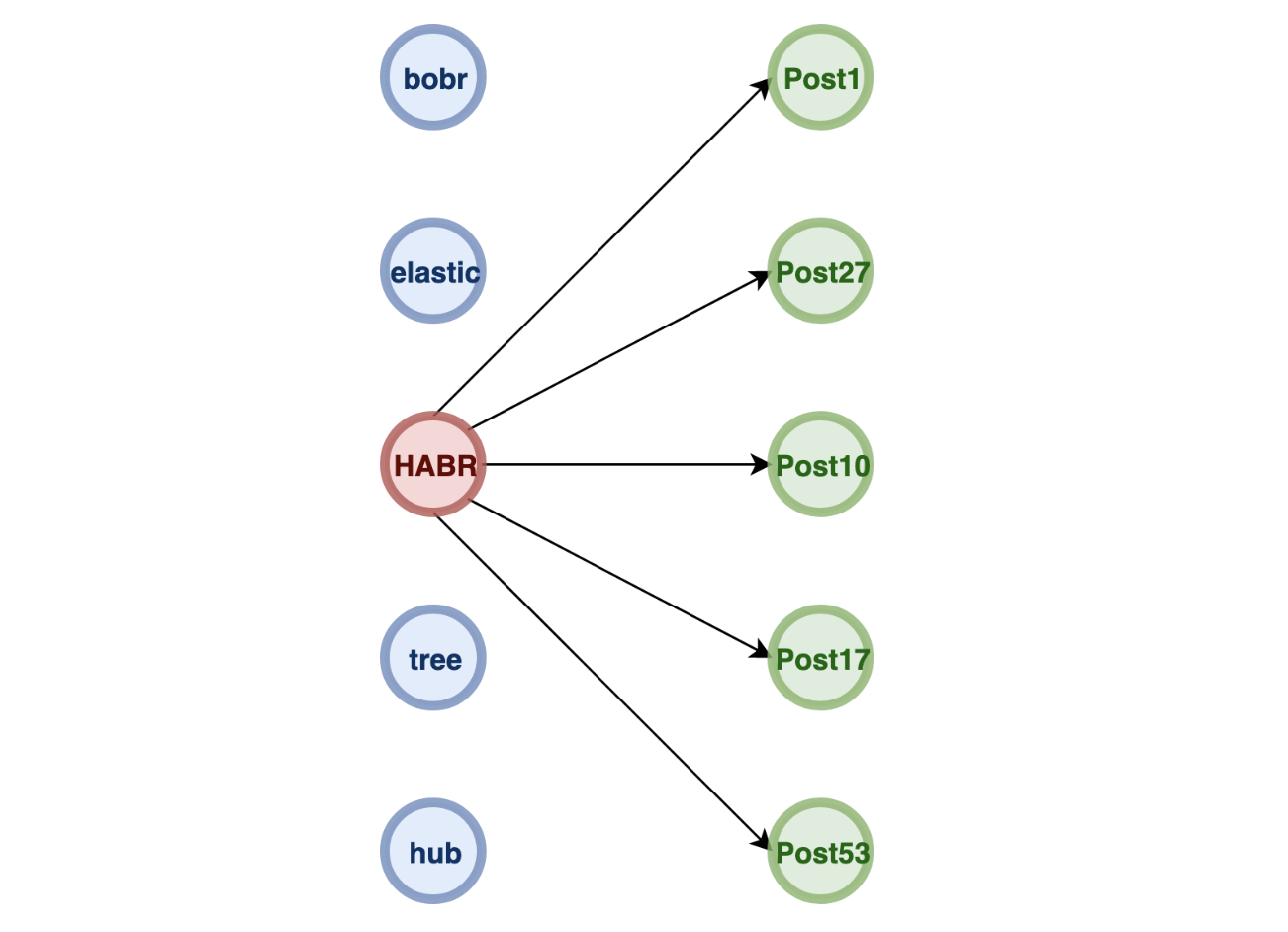
Elasticsearch использует индексы Lucene для хранения данных и поиска
Возможно шардирование
Index — это одновременно и распределенная база и механизм управления и организации данных, это именно логическое пространство. Индекс содержит один или более шардов, их совокупность и является хранилищем.
Elasticsearch SQL MongoDB Index Database Database Mapping/Type Table Collection Field Column Field Object(JSON) Tuple Object(BSON) Но существуют отличия в использовании этих абстракций. Рассмотрим еще один классический пример. У пользователя системы может храниться очень много информации, и мы решаем создавать новую базу для каждого пользователя. Это звучит дико! Но на самом деле в Elasticsearch это распространенная и даже хорошая практика. Индекс это довольно легкий механизм и лучше разделять большие данные, тем более, когда это логически оправдано. Системе проще работать с небольшими индексами чем с разросшейся базой для всего. Например, так вы можете создавать отдельный индекс для логов на каждый день и это широко используется.
По умолчанию количество шардов для индекса будет равным 5, но его всегда возможно изменить в настройках
index.number_of_shards: 1или с помощью запроса шаблонов индекса.
PUT _template/all
{
"template": "*",
"settings": {
"number_of_shards": 1
}
}
Важно управлять этим значением. Всегда принимайте решения с точки зрения параллельной обработки.
Каждый шард способен хранить примерно 232 или 4294967296 записей, это значит, что скорее всего вы упретесь в лимит вашего диска. Однако стоит понимать, все шарды будут участвовать в поиске и если мы будем искать по сотне пустых, потратим время впустую. Если шарды будут слишком большими мы так же будем тратить лишнее время на поиск, а так же операций перемещения и индексации станут очень тяжелыми.
Забегая вперед. Со временем Elasticsearch двигает и изменяет шарды, объединяя дробные и мелкие в большие. Следите за размером ваших шардов, при достижении 10ГБ производительность значительно падает.
Кластер
Ранее мы решили, что за операции поиска и индексации отвечает отдельный инстанс Lucene (шард). Для того, чтобы обращаться к распределенной системе шардов, нам необходимо иметь некий координирующий узел, именно он будет принимать запросы и давать задания на запись или получение данных. То есть помимо хранения данных мы выделяем еще один вариант поведения программы — координирование.
Таким образом мы изначально ориентируемся на два вида узлов — CRUD-узлы и координирующие узлы. Назовем их data node и coordinating node. У нас есть куча машин объединенных в сеть и все это очень напоминает кластер.
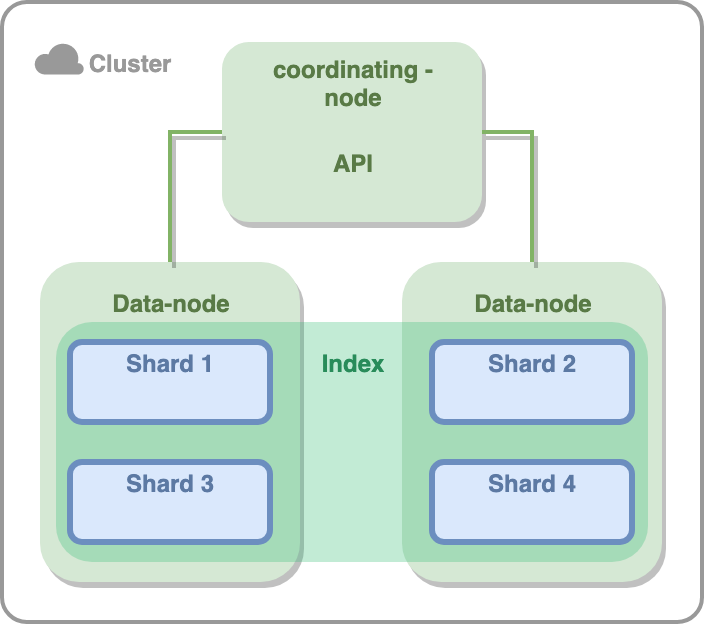
Для того чтобы объединить узлы в кластер они должны соответствовать ряду требований:
- Ноды должны иметь одинаковую версию
- Имя кластера
cluster.nameв конфигурации должно быть одинаковым
Конфигурация читается из файла elasticsearch.yml и переменных среды. Здесь мы можете настроить почти все, что касается неизменных в рантайме свойств ноды.
Данные можно разделить на горячие и холодные:
Начиная с версии 6.7 Elasticsearch предлагает механизм управления жизненным циклом. Для этого доступны три типа нод — hot, warm и cold.
Существует рекомендация по выбору аппаратных конфигураций для каждого из типов. Например hot-ноды должны иметь быстрые SSD, для warm и cold достаточно HDD-диска. Оптимальные соотношения память/диск будут следующими:
- hot — 1:30
- warm — 1:100
- cold — 1:500
Для того чтобы определить тип ноды как data node необходимо установить значение в конфигурации
node.data: true, при этом рекомендуется выделять ноду под один конкретный тип, для повышения стабильности и производительности кластера.В Elasticsearch все узлы неявно являются координирующими. Однако, стоит выделять отдельные coordinating-ноды, не выполняющие других операций. Забегая вперед, такие ноды можно определить, установив значения всех типов в
false.
Управление кластером
Предположим, возможность coordinating-нодам управления состоянием кластера. Один узел примет решение о перемещении шарда на одну data-ноду, а второй о перемещении того же на другую. Список возможных общекластерных действий может быть довольно широким, а список возможных конфликтов еще шире.
Значит нужна master-node. Активный мастер всегда должен быть один, он будет управлять топологией кластера: создавать новый индекс, выделять и распределять шарды, перемещать их и объединять в случае необходимости. Мастер всегда знает все о состоянии кластера.
В кластере Elasticsearch обязательно должен быть как минимум один узел отвечающий требованиям master node. Для этого в конфигурации ноды необходимо установить значение node.master: true.
Master-ноды отвечают за важные, но довольно легкие общекластерные действия. Это означает, что они требуют большого ресурса и высокой стабильности от физической ноды. В кластерах от 10 нод необходимо всегда выделять отдельные only-master узлы.