CAP Теорема
CAP теорема
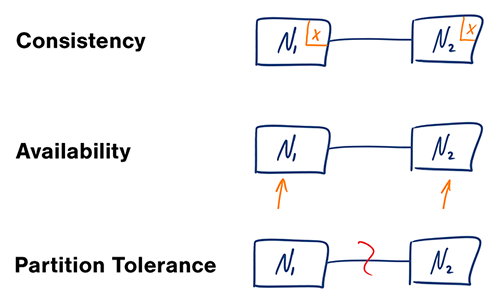
Consistency (Консистентность) - каждый запрос на чтение получает в ответе либо последнюю записанную версию, либо ошибку
Availability (Доступность) - каждый запрос получает ответ, не гарантируется, что это будет последняя записанная версия
Partition Tolerance (Устойчивость к частичным отказам) - система продолжает работает не смотря на частичные отказы из-за сети.
Сеть всегда нестабильна, так что Partition Tolerance должна быть всегда! Выбор есть только между C и A
Варианты теоремы
CP - Консистентность и Устойчивость
Запрос к распределенному узлу может получить либо ответ с самыми актуальными данными, либо ошибку с таймаутом. Подходит для систем, которым нужны атомарные чтение и запись.
AP - Доступность и Устойчивость
Запрос на чтение возвращает последнюю доступную версию данных.
Запросу на запись требуется время, чтобы разойтись по всем распределенным узлам.
Подходит системам, которым достаточно конечной консистентности (eventual consistency), а так же системам, которые должны выдерживать внешние сбои.
Применяем на практике
Посмотрим на Postgresql
Следующие пункты относятся к абстрактной распределенной БД Postgresql.
- Репликация Master-Slave — одно из распространенных решений
- Синхронизация с Master в асинхронном / синхронном режиме
- Система транзакций использует двухфазный коммит для обеспечения consistency
- Если возникает partition, вы не можете взаимодейстовать с системой (в основном случае)
Таким образом, система не может продолжать работу в случае partition, но обеспечивает strong consistency и availability. Это система CA!
Посмотрим на MongoDB
Следующие пункты относятся к абстрактной распределенной БД MongoDB.
- MongoDB обеспечивает strong consistency, потому что это система с одним Master узлом, и все записи идут по умолчанию в него.
- Автоматическая смена мастера, в случае отделения его от остальных узлов.
- В случае разделения сети, система прекратит принимать записи до тех пор, пока не убедится, что может безопасно завершить их.
Таким образом, система может продолжать работу в случае разделения сети, но теряется CAP-availability всех узлов. Это CP система!
Посмотрим на Cassandra
Cassandra использует схему репликации master-master, что фактически означает AP систему, в которой разделение сети приводит к самодостаточному функционированию всех узлов.
Казалось бы всё просто… Но это не так.
Проблемы CAP
На тему проблем в CAP теореме написано множество подробных и интересных статей, здесь, на Хабре, поэтому я оставлю ссылку на CAP больше не актуален и мифы о CAP теореме. Обязательно почитайте их, но относитесь к каждой статье, как к своего рода новому взгляду и не принимайте слишком близко к сердцу, потому что одни ругают, другие хвалят. Сам же я не буду слишком углублятся, а постараюсь выдать некоторую необходимую компиляцию.
Итак, проблемы CAP теоремы:
- Далёкие от реального мира определения
- В рамках разработки, выбор в основном лежит между CP и AP
- Множество систем — просто P
- Чистые AP и CP системы могут быть не тем, что ожидаешь
Availability в CAP, исходя из определения имеет две серьёзные проблемы. Первая — нет понятия частичной доступности, или какой-то её степени (проценты например), а есть только полная доступность. Вторая проблема — неограниченное время ответа на запросы, т.е. даже если система отвечает час, она всё ещё доступна.
Коммуникация узлов между собой обычно происходит через асинхронную сеть, которая может задерживать или удалять сообщения. Интернет и все наши центры обработки данных обладают этим свойством, и это не маловероятные инциденты, поэтому CA системы в рамках разработки рассматриваются крайне редко.
Многие системы — просто P
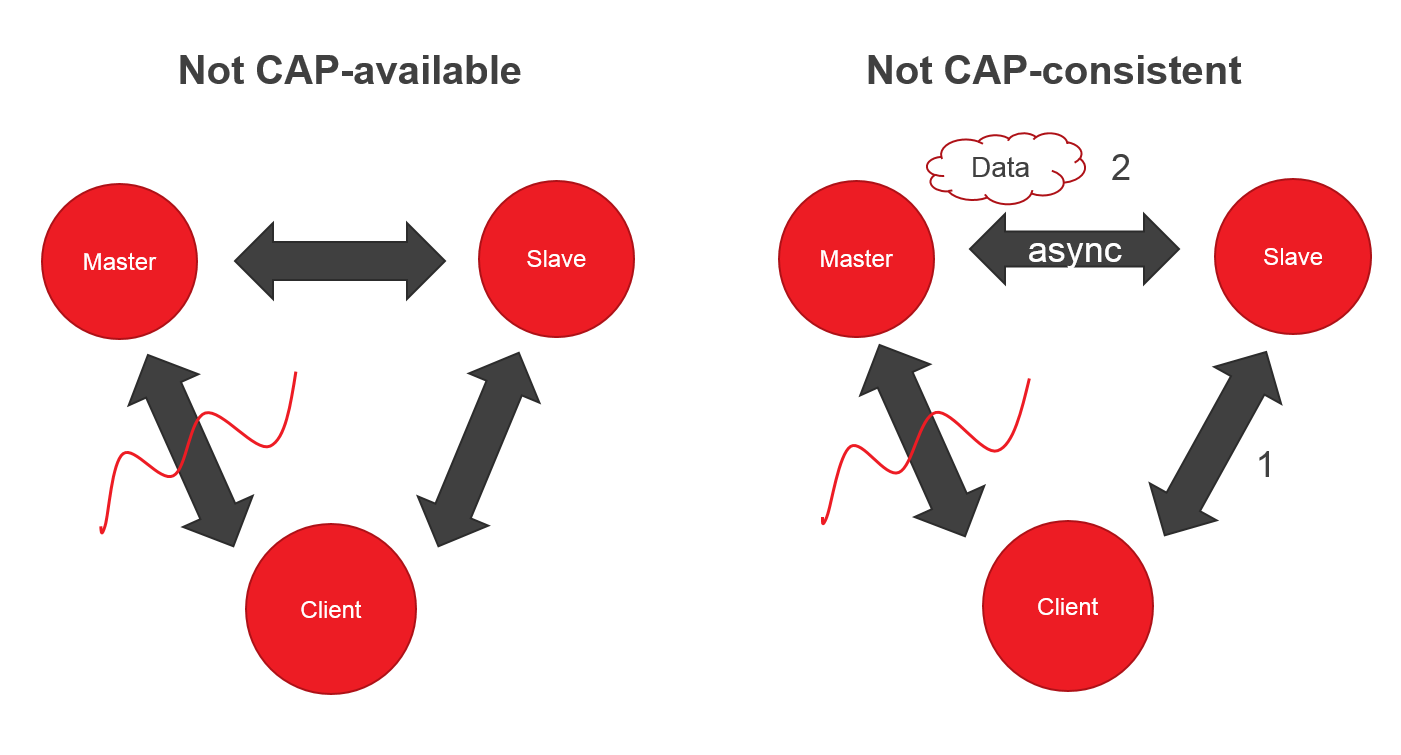
Представьте систему, в которой два узла (Master, Slave) и клиент. Если вдруг вы потеряли связь с Master, клиент может читать из Slave, но не может писать — нет CAP-availability.
Ок, вроде CP система, но если Master и Slave синхронизируются асинхронно, то клиент, может запросить данные от Slave раньше успешной синхронизации — теряем CAP-consistency.
PACELC
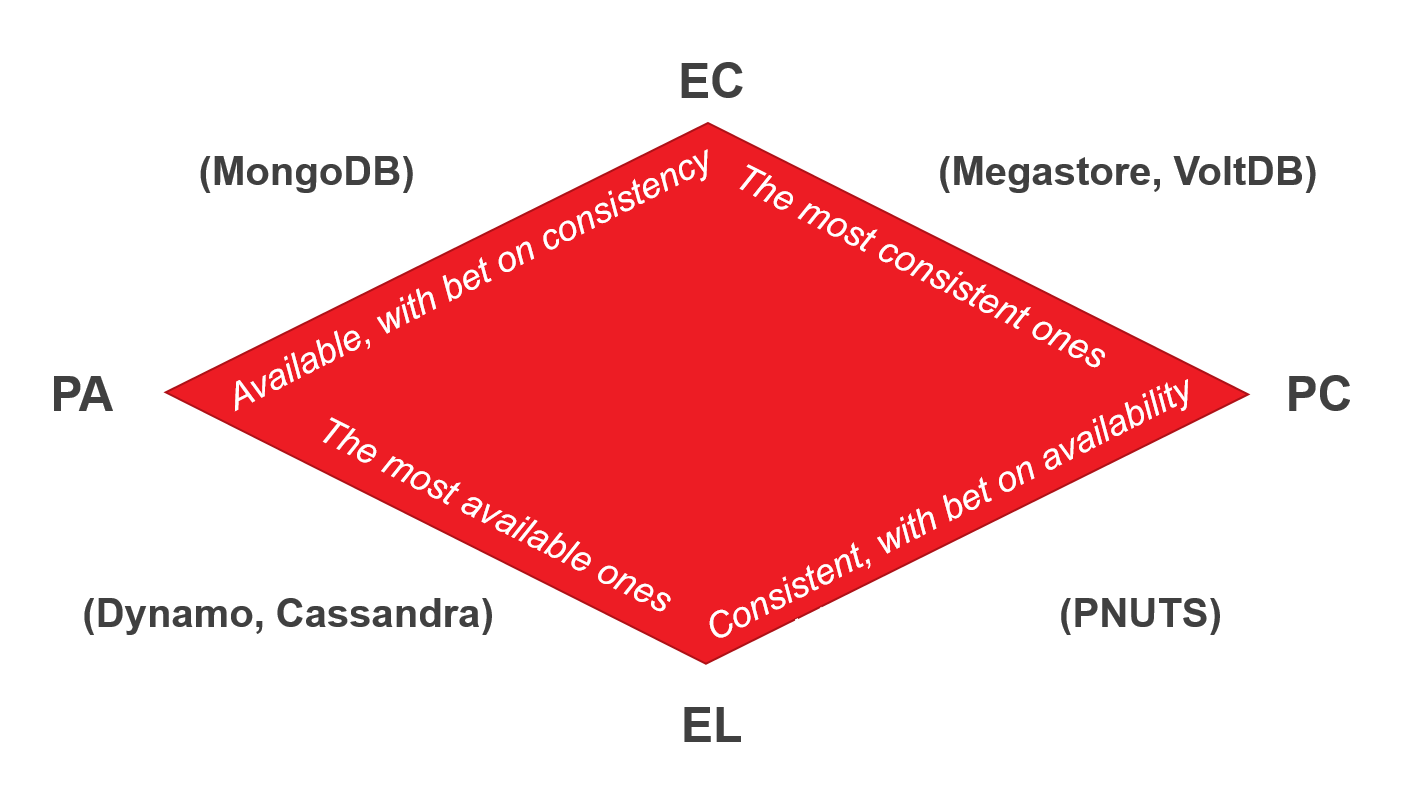
Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году. Поскольку теорема PACELC основана на CAP, она также использует его определения.
Вся теорема сводится к IF P -> (C or A), ELSE (C or L).
Latency — это время, за которое клиент получит ответ и которое регулируется каким-либо уровнем consistency. Latency (задержка), в некотором смысле представляет собой степень доступности.
Свежий взгляд
Теперь, когда мы знаем о большинстве подводных камней, давайте попробуем рассмотреть те же самые популярные системы баз данных через призму полученных знаний.
Postgresql
Postgresql действительно допускает множество различных конфигураций системы, поэтому их очень сложно описать. Давайте просто возьмем классическую Master-Slave репликацию с реализацией через Slony.
- Система работает в соответствии с ACID (существует пара проблем с двухфазным коммитом, но это вне рамок статьи).
- В случае разрыва связи, Slony попытается переключиться на новый Master, и у нас есть новый мастер с его согласованностью.
- Когда система функционирует в нормальном режиме, Slony делает все, чтобы достичь strong consistency. На самом деле, ACID — причина большой задержки в этой системе.
- Классификация системы — PC / EC (A).
MongoDB
Давайте узнаем что-то новое о MongoDB:
- Это ACID в ограниченном смысле на уровне документа.
- В случае распределенной системы — it's all about that BASE.
- В случае отсутствия разделений сети, система гарантирует, что чтение и запись будут согласованными.
- Если Master узел упадёт или потеряет связь с остальной системой, некоторые данные не будут реплицированы. Система выберет нового мастера, чтобы оставаться доступной для чтения и записи. (Новый мастер и старый мастер несогласованы).
- Система рассматривается как PA / EC (A), так как большинство узлов остаются CAP-available в случае разрыва. Помните, что в CAP MongoDB обычно рассматривается как CP. Создателль PACELC, Даниэль Дж. Абади, говорит, что существует гораздо больше проблем с согласованностью, чем с доступностью, поэтому PA.
Cassandra
- Предназначена для «скоростного» взаимодействия (low-latency interactions).
- ACID на уровне записи.
- В случае распределенной системы — it's all about that BASE.
- Если возникает разрыв связи, остальные узлы продолжают функционировать.
- В случае нормального функционирования — система использует уровни согласованности для уменьшения задержки.
- Система рассматривается как PA / EL (A).
Паттерны консистентности
Слабая консистентность
Слабая консистентность (Weak Consistency) означает, что после записи запросы на чтение могут увидеть или не увидеть последние данные. Применяется самый эффективный подход на момент чтения
Подходит для VoIP, видеоконференций, мультиплеера. В таких системах после отказа связи на несколько секунд клиент не будет получать потерянные данные, только текущие.
Конечная консистентность
(Eventual consistency)
После записи, запросы на чтение увидят последние данные в конечном итоге. Данные реплицируются асинхронно
Используется в DNS и электронной почте. Подход хорошо подходит для высокодоступных систем.
Сильная консистентность
(Strong consistency)
После записи, запросы на чтения сразу увидят данные.
Работает в файловых системах и реляционных БД. Подход применяется в системах, которым необходимы транзакции.
Паттерны доступности
Отказоустойчивость
Активная - пассивная
Активный и пассивный сервера обмениваются heartbeat запросами. Если активный сервер не отвечает на heartbeat, то пассивный сервер перехватывает IP адрес активного и сам становится активным.
Только активный сервер получает клиентский трафик. Время отказа вычисляется временем переключения из пассивного режима в активный. Пассивный сервер может находиться в горячем (hot) режиме, тогда ему нужно меньше времени на переключение. Либо в холодном (cold), тогда ему нужно дополнительное время на старт.
Активный - активный
Оба сервера получают клиентский трафик. Он распределяется между серверами некоторым образом.
Если сервера выставлены наружу, то DNS сервер должен знать IP адреса обоих. Если они приватные, то приложение должно знать об обоих.
Недостатки
- Добавляет больше железа и сложности в структуре.
- Возможна потеря данных, если активный сервер не успеет реплицировать данные для пассивного перед отказом.
Репликация
TODO
Раскрыта в главе по базы данных